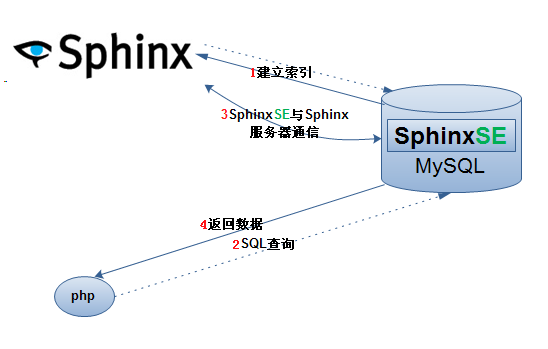
什么是sphinx?
Sphinx是一个独立的全文索引引擎,专门用来对大数据量的大文本字段类型建索引的软件。
sphinx的使用流程:
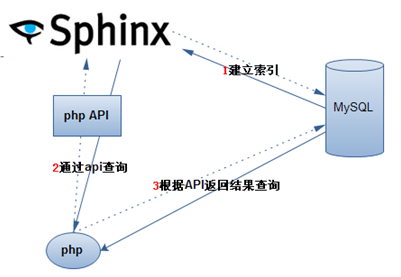
如:查询出所有歌词中带有冬天。
1. 先查询sphinx中的索引,然后sphinx会返回所有带冬天的歌曲的id
2. 再根据id 查询mysql数据库
SELECT * FROM songs WHERE id IN (1,2,3,4)
这里因为id上有索引,所以这个SQL会非常快!绝对比直接执行
SELECT * FROM songs WHERE gechi LIKE “%冬天%”快(前提:数据量大的时候)
最常用的两个命令:
indexer.exe : 建索引
searchd.exe : sphinx 的服务器(在建完索引之后,启动服务器提供索引查询的服务器)
为数据创建建索引
流程:
- 先连接MYSQL
- 执行前置SQL (sql_query_pre)
- 执行主查询取出数据 (sql_query)
- 对取出的数据建立索引
- 执行后置SQL
- 关闭MYSQL的连接
本文章用到的sphinx版本(此版本在PHP7中运行,构造方法有问题,需更改下):
链接:https://pan.baidu.com/s/1LRwVz99ScpWkSKGG43ZXSg提取码:gjv3
第一步:修改配置文件



- #源定义 (每一个数据源要对应一个index) ,一个配置文件中可以定义多个数据源
- source songs
- {
- type = mysql
- sql_host = localhost
- sql_user = root
- sql_pass = root
- sql_db = test
- sql_port = 3306
- # 要建索引之前执行的SQL语句
- sql_query_pre = SET NAMES utf8
- # 这个SQL取出的数据就是要创建索引的数据
- # 第一个字段必须是一个非负、非空并且唯一的数字(主键)
- # 其它的字段就是要创建索引的字段
- # 一个数据源中只能有一个主查询
- sql_query = SELECT id,title,content FROM curl_songs
- }
-
- # 定义之后创建宾索引的存储位置等信息
- index songs
- {
- source = songs #对应的source名称
- # 存放到d:/sphinx/data下,然后索引文件的名字叫做songs
- path = D:/coreseek/data/songs # 索引文件存储的位置
- docinfo = extern
- mlock = 0
- morphology = none
- min_word_len = 1
- html_strip = 0
- # 中文的语言包,指定到coreseek软件的etc目录
- charset_dictpath = D:/coreseek/etc/
- # 只支持UTF-8
- charset_type = zh_cn.utf-8
- }
- indexer
- {
- mem_limit = 128M
- }
-
- searchd
- {
- # 监听的端口号
- listen = 9312
- # 连接超时的时间
- read_timeout = 5
- # 允许多少个并发的查询(SPHINX)
- max_children = 30
- # sphinx最大返回多少条记录
- max_matches = 1000
- seamless_rotate = 0
- preopen_indexes = 0
- unlink_old = 1
- # 日志文件的位置
- log = D:/coreseek/log/searchd_mysql.log
- # 查询日志的位置
- query_log = D:/coreseek/log/query_mysql.log
- }
第二步:在命令行中运行indexer.exe程序
indexer.exe -c d:/sphinx/sphinx.conf songs --> 为songs这个数据源建索引
indexer.exe -c d:/sphinx/sphinx.conf --all --> 为配置文件中所有的数据源都创建索引
启动服务器
searchd.exe -c d:/sphinx/sphinx.conf
服务器还有的参数:
searchd -c 配置文件 索引名称
服务器端默认监听 9312 端口。常用命令:
-c : 指定配置文件路径
--stop : 停止当前服务
--status : 查看当前状态
--install : 安装为 windows 服务
--delete: 删除windows服务
--port port: 监听的端口
--index indexName : 只查询某个索引,默认查询所有索引
php demo
- <?php
- $data = [];
- {
- require('sphinxapi.php');
- $sc = new SphinxClient(); // 生成客户端
- $sc->setServer('localhost', 9312); // 设置服务器
- // 第一参数:查询的词
- // 第二参数:要从哪个数据源中查询
- $index = 'songs';
- $sc->SetLimits(0, 3); // 分页
- $res = $sc->query($_GET['k'], $index);
- if($res['total_found'] > 0)
- {
- $sql = "SELECT title,content FROM curl_songs WHERE id IN($ids)";
- 'before_match' => "<font color='red'>", // 在匹配项前面加的字符串
- 'after_match' => '</font>', // 在匹配后加的字符串
- 'limit' => 150, // 摘要显示多少个字符
- ));
- $data[] = $row;
- }
- }
- }
- ?>
- <html>
- <head>
- <style>
- dt{padding:5px;background:#EEE;}
- </style>
- </head>
-
- <body>
- <form method="GET" action="?">
- 查询:<input type="text" name="k" value="<?php echo $_GET['k'] ?? ''; ?>" /><input type="submit" value="查询" />
- 查询时间:<?php echo $res['time'] ?? ''; ?>
- 共查询到:<?php echo $res['total_found'] ?? ''; ?> 首歌
- </form>
- <hr />
-
- <dl>
- <dt><?php echo $d[0]; ?></dt>
- <dd><?php echo $d[1]; ?></dd>
- <?php endforeach; ?>
- </dl>
- </body>
- </html>
匹配模式
- SPH_MATCH_ALL : 匹配所有查询词(默认)
如“冬天的雪”,并不会匹配 “我爱冬天”,但可以匹配 “我的朋友,爱冬天,和雪”。因为“冬天的雪” 被分成 “冬天”,“的”,“雪”三个词,匹配条件是同时包含这三个词,“我爱冬天”里只包含一个“冬天”
- SPH_MATCH_ANY:匹配查询词中的任意一个。
如“冬天的雪”,并会匹配 “我爱冬天”。"冬天的雪“ -》 ”冬天“ ”的“ ”雪“因为“我爱冬天”里有一个“冬天”相匹配。
- SPH_MATCH_PHRASE:将整个查询词看做一个词组,要完全匹配
如“冬天的雪”,不会匹配 “我的朋友,爱冬天,和雪”,虽然都包含同样的词。
- SPH_MATCH_BOOLEAN : 将查询看作一个布尔表达式
如:hello | world查询“手机”,或“冬天”,:
- <?php
- $sc = new SphinxClient();
- $res = $sc->query("手机|冬天");
- SPH_MATCH_EXTENDED : 查询看做一个sphinx的表达式
支持 @字段 查询如,查询title包含 abc , content 包含 bcd的:'@title abc @content bcd'
PHP中通过setMatchMode函数来设置,如:
- <?php
- $sc = new SphinxClient();
- $sc->setMatchMode(SPH_MATCH_ANY);
常用函数
- buildExcerpts : 创建文档摘要。
- close : 关闭连接
- query : 执行查询
- getLastError : 返回上一条错误信息
- open : 建立到服务器端的持久连接
- setArrayResult : 设置返回结果格式
- setLimits : 设置返回结果数量与偏移
- setMatchModel: 设置查询模式
- updateAttributes : 更新文档属性
- setGroupBy : 设置分组属性
- setFilter : 设置过滤器
更多 API查看:http://www.php.net/manual/zh/book.sphinx.php
自动索引的更新:sphinx的主索引+增量索引
第一步:先建一个表用来存当前已经创建索引的最后一条记录的ID
- CREATE TABLE a
- (
- id int UNSIGNED NOT NULL AUTO_INCREMENT,
- max_id int UNSIGNED NOT NULL DEFAULT '0',
- # 最后一条已经创建了索引的ID
- PRIMARY KEY (id)
- )
第二步:修改配置文件
主数据源中添加sql_query_post记录下最后的ID
再添加一个增量部分的数据源
- #源定义 (每一个数据源要对应一个index) ,一个配置文件中可以定义多个数据源
- source songs
- {
- type = mysql
- sql_host = localhost
- sql_user = root
- sql_pass = root
- sql_db = test
- sql_port = 3306
- # 要建索引之前执行的SQL语句
- sql_query_pre = SET NAMES utf8
- # 这个SQL取出的数据就是要创建索引的数据
- # 第一个字段必须是一个非负、非空并且唯一的数字(主键)
- # 其它的字段就是要创建索引的字段
- # 一个数据源中只能有一个主查询
- sql_query = SELECT id,title,content FROM curl_songs
- #当朱查询执行完之后执行的sql语句
- #把最后一条记录的id存储到a表
- sql_query_post = REPLACE INTO a(id, max_id) SELECT 1, max(id) From curl_post
- }
-
- # 定义之后创建宾索引的存储位置等信息
- index songs
- {
- source = songs #对应的source名称
- # 存放到d:/sphinx/data下,然后索引文件的名字叫做songs
- path = D:/coreseek/data/songs # 索引文件存储的位置
- docinfo = extern
- mlock = 0
- morphology = none
- min_word_len = 1
- html_strip = 0
- # 中文的语言包,指定到coreseek软件的etc目录
- charset_dictpath = D:/coreseek/etc/
- # 只支持UTF-8
- charset_type = zh_cn.utf-8
- }
-
- #增量索引的数据源
- source songs_add
- {
- type = mysql
- sql_host = localhost
- sql_user = root
- sql_pass = root
- sql_db = test
- sql_port = 3306
- sql_query_pre = SET NAMES utf8
- #只取出增量部分建索引
- sql_query = SELECT id,title,content FROM curl_songs where id > select max_id from a
- #再把最后一条记录id更新到a表
- sql_query_post = REPLACE INTO a(id, max_id) SELECT 1, max(id) From curl_post
- }
-
- index songs_add
- {
- source = songs #对应的source名称
- path = D:/coreseek/data/songs # 索引文件存储的位置
- docinfo = extern
- mlock = 0
- morphology = none
- min_word_len = 1
- html_strip = 0
- charset_dictpath = D:/coreseek/etc/
- charset_type = zh_cn.utf-8
- }
- indexer
- {
- mem_limit = 128M
- }
-
- searchd
- {
- # 监听的端口号
- listen = 9312
- # 连接超时的时间
- read_timeout = 5
- # 允许多少个并发的查询(SPHINX)
- max_children = 30
- # sphinx最大返回多少条记录
- max_matches = 1000
- seamless_rotate = 0
- preopen_indexes = 0
- unlink_old = 1
- # 日志文件的位置
- log = D:/coreseek/log/searchd_mysql.log
- # 查询日志的位置
- query_log = D:/coreseek/log/query_mysql.log
- }
第三步:
1. indexer.exe -c d:/sphinx/sphinx.conf songs
2. 定期执行以下步骤:
indexer.exe -c d:/sphinx/sphinx.conf songs_zl --> 为增量的数据创建索引
indexer.exe --merge songs songs_zl --rotate --> --rotate:选择phinx服务器索引有更新要替换新的索引
replace into 的意思:如果这条记录不存在就插入这条记录,如果已经存在就更新这条记录
SphinxSE